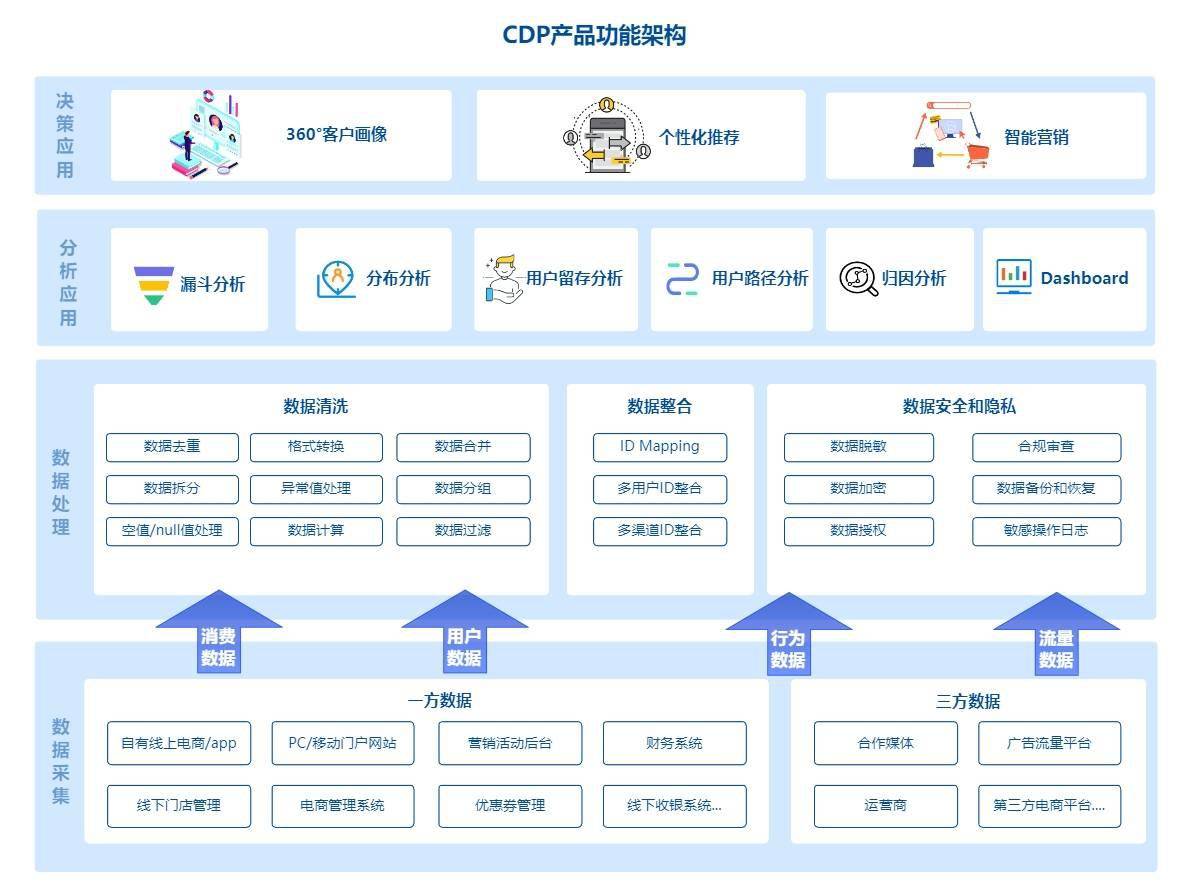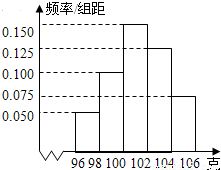
在現代數據驅動型應用中,實時數據交換與處理能力已成為核心競爭力。Apache Kafka作為分布式事件流平臺,與動態數據網格(Dynamic Data Grid)的結合,為構建高性能、可擴展、低延遲的流式數據處理架構提供了強大支撐。
一、核心組件:Kafka與動態數據網格
Apache Kafka是一個高吞吐量、可水平擴展的分布式發布-訂閱消息系統。它通過主題(Topic)組織數據流,生產者(Producer)將數據發布到主題,消費者(Consumer)從主題訂閱并處理數據。其持久化日志、分區機制和副本策略確保了數據的可靠性和有序性。
動態數據網格(通常以Hazelcast、Apache Ignite等內存數據網格為代表)是一種分布式內存計算和存儲層。它將數據存儲在集群節點的內存中,提供極低延遲的數據訪問,并支持分布式計算、事件監聽、數據分區與復制等功能。其“動態”特性體現在節點可動態加入或離開集群,數據自動重新平衡。
二、架構融合:流式數據交換與處理的協同
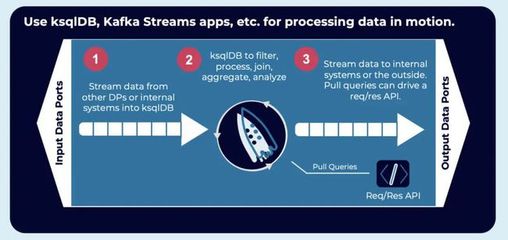
典型的整合架構中,Kafka充當統一、可靠的數據流中樞。來自各類源頭(如數據庫變更日志、應用日志、物聯網設備、微服務事件)的數據實時寫入Kafka主題。動態數據網格則扮演近數據處理的角色,它可以作為Kafka的消費者,訂閱相關主題,將流數據實時加載到內存網格中。
這種模式實現了清晰的責任分離:Kafka負責數據的持久化、有序傳輸和緩沖;數據網格則提供內存高速訪問、復雜事件處理(CEP)、實時查詢和狀態維護。例如,一個實時風控系統可以將交易事件流通過Kafka傳輸,數據網格中的計算節點實時消費這些事件,在內存中維護用戶畫像、交易模式等狀態,并即時執行風險規則計算。
三、關鍵優勢與實現模式
- 極致的性能與低延遲:數據網格的內存存儲將熱數據保持在RAM中,結合Kafka的高吞吐量,使端到端的處理延遲可降至毫秒級。
- 彈性和可擴展性:兩者均為分布式設計。Kafka可通過增加分區和代理(Broker)水平擴展吞吐量;數據網格可通過添加節點線性擴展存儲與計算能力,并自動處理數據再平衡。
- 狀態化流處理:數據網格為流處理提供了分布式、高可用的狀態存儲。這對于窗口聚合、會話分析、機器學習模型狀態等需要維護上下文的應用至關重要。
- 事件驅動與數據本地性:數據網格支持監聽其內部數據變更事件。結合Kafka的流輸入,可以構建事件驅動架構,并在數據所在的網格節點上直接執行計算,最大化利用數據本地性。
常見的實現模式包括:
- 緩存與物化視圖:將Kafka流中的數據實時聚合、轉換后存入數據網格,為前端應用提供亞秒級查詢響應的物化視圖。
- 復雜事件處理引擎:利用數據網格的分布式計算能力,在內存中并行處理多個Kafka事件流,檢測復雜模式。
- 微服務狀態共享與解耦:多個微服務通過Kafka交換事件,并將共享狀態(如用戶會話、庫存快照)存儲在數據網格中,避免服務間緊耦合的直接調用。
四、挑戰與最佳實踐
盡管優勢顯著,該架構也帶來挑戰:
- 架構復雜性:需要運維兩個分布式系統,對監控、部署和故障排查要求更高。
- 數據一致性:在分布式環境中,需要仔細設計事務語義和最終一致性模型。可采用Kafka事務API與數據網格的分布式事務或樂觀鎖結合。
- 內存管理:數據網格容量受物理內存限制,需有選擇地存儲熱數據,并設計數據逐出(Eviction)策略。
最佳實踐建議:
- 明確數據生命周期,將Kafka用于長期事件日志存儲,數據網格用于實時處理所需的活躍數據集。
- 利用Kafka Connect或自定義消費者,高效地將數據從Kafka加載到數據網格。
- 實施細粒度的監控,涵蓋Kafka集群健康(如滯后消費者)、數據網格內存使用、節點狀態及端到端延遲。
- 設計容錯機制,確保在節點故障時,Kafka的消費位移(Offset)和數據網格的副本能保障處理不中斷、數據不丟失。
Kafka與動態數據網格的協同,構建了一個從高效流式數據交換到實時智能處理的完整鏈路。這種架構完美契合了實時數據分析、實時個性化推薦、物聯網監控、金融交易處理等對時效性要求極高的場景。通過合理的設計與運維,組織能夠駕馭持續增長的數據洪流,并從中提取即時價值,驅動業務敏捷決策與創新。