在構建產品數據運營體系的過程中,數據處理是承上啟下的核心環節。它連接了原始數據的采集與最終的分析應用,其質量與效率直接決定了后續洞察的準確性與決策的有效性。本文將聚焦實戰,詳細拆解構建產品數據運營體系中,數據處理環節的關鍵步驟與最佳實踐。
步驟一:明確數據處理目標與范圍
在開始任何技術操作前,必須明確本次數據處理的目標。是為用戶行為分析準備事件數據?還是為商業報表整合交易數據?明確目標后,界定數據源的范圍,例如確定需要處理的是App端埋點日志、數據庫業務表,還是第三方API數據。這決定了后續技術棧和流程的設計。
步驟二:建立原始數據存儲與接入規范
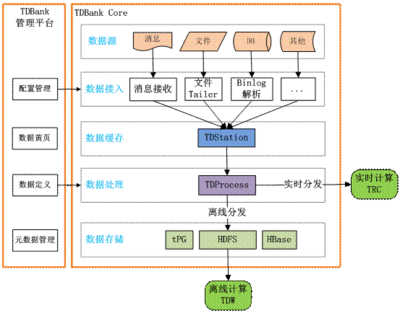
確保從各端(Web、App、服務器等)采集的原始數據能夠穩定、完整地流入數據倉庫或數據湖。建立統一的接入規范,包括數據格式(如JSON Schema)、傳輸協議、字段命名規則等。使用如Kafka、Flume等消息隊列或日志收集工具,實現數據的實時或準實時接入,為后續處理提供“原料”。
步驟三:實施數據清洗與初步校驗
原始數據往往包含大量“噪音”,如缺失值、異常值、格式錯誤、重復記錄等。此步驟需制定清晰的清洗規則,例如:
- 缺失值處理:根據業務邏輯,采用填充(如用平均值、中位數)、插值或直接剔除。
- 異常值檢測:通過統計方法(如3σ原則)或業務規則(如訂單金額不可能為負)識別并處理。
- 格式標準化:統一時間戳格式、用戶ID類型、枚舉值映射等。
初步校驗則確保數據在進入核心處理流程前符合最基本的質量要求。
步驟四:進行數據集成與關聯
產品數據通常分散在不同系統和表中。此步驟旨在通過關鍵鍵(如用戶ID、訂單ID)將不同來源的數據關聯起來,形成完整的用戶旅程或業務實體視圖。例如,將用戶行為事件表與用戶屬性表、商品信息表進行關聯,為分析提供豐富上下文。
步驟五:構建數據模型與維度建模
這是提升數據可用性的關鍵。根據分析需求,采用維度建模等方法,構建主題明確的數據模型,如星型模型或雪花模型。常見模型包括:
- 用戶事件模型:圍繞“誰在何時何地做了什么”,清晰定義事件、屬性和用戶維度。
- 業務聚合模型:針對核心業務指標(如GMV、DAU),預計算聚合表,提升查詢效率。
良好的模型設計是高效分析和數據產品(如報表、看板)的基礎。
步驟六:實現數據轉換與計算
根據數據模型和業務規則,編寫轉換邏輯(通常使用SQL或Spark等計算引擎),生成可直接用于分析的中間表或寬表。這包括:
- 派生字段計算:如計算用戶生命周期階段、會話時長、轉化漏斗步驟等。
- 指標聚合:如按天、按渠道統計新增用戶數、活躍用戶數、留存率等。
- 復雜業務邏輯編碼:將產品業務規則固化為可重復執行的數據處理代碼。
步驟七:建立數據質量監控體系
數據處理不是一勞永逸的。必須建立持續的數據質量監控,包括:
- 完整性監控:每日數據量是否在正常波動范圍內?關鍵字段缺失率是否超標?
- 準確性監控:核心指標計算結果是否與業務系統核對一致?
- 及時性監控:數據是否按時產出?
通過設置閾值和報警機制(如郵件、釘釘/飛書機器人),確保問題能被及時發現和響應。
步驟八:設計分層數據存儲架構
為便于管理和使用,通常將處理后的數據分層存儲:
- ODS(操作數據層):存放近原始狀態的接入數據。
- DWD(明細數據層):存放經過清洗、集成、關聯后的高質量明細數據。
- DWS(匯總數據層):存放面向主題的輕度匯總數據。
- ADS(應用數據層):存放為特定報表或數據產品高度聚合的結果數據。
分層架構確保了數據流向清晰、權責分明,并平衡了存儲成本與查詢效率。
步驟九:實施任務調度與依賴管理
數據處理任務往往存在復雜的依賴關系(如DWD層任務需在ODS層任務完成后啟動)。需要使用調度工具(如Airflow、DolphinScheduler)來編排任務流,設置執行周期、依賴和失敗重試機制,實現自動化、可靠的數據流水線。
步驟十:建立元數據管理與數據字典
隨著數據表和處理任務的增多,必須對元數據進行管理。記錄每張表的字段含義、業務口徑、負責人、產出時間、血緣關系(上游來源和下游應用)等信息,形成團隊共享的數據字典。這極大降低了溝通成本,是數據資產化的重要一步。
步驟十一:持續迭代與優化
數據處理體系需要伴隨業務發展而持續迭代。定期回顧:
- 處理流程是否能滿足新的分析需求?
- 計算性能和成本是否在可接受范圍?
- 數據質量是否穩定?
根據反饋優化模型、調整清洗規則、升級技術架構,使數據處理能力始終保持活力。
****
數據處理是產品數據運營體系的“煉油廠”,它將雜亂無章的原始數據提煉成高質量、易理解、可信任的信息燃料。通過系統性地踐行以上十一個步驟,團隊能夠構建一個穩健、高效、可擴展的數據處理管道,為深入的數據分析與精準的業務決策打下堅實的基礎,真正驅動產品增長與用戶體驗優化。